
[Kotlin] 동시성 문제와 해결방법
소프트웨어를 개발하는 데 있어서, 성능을 높이기 위해 가장 흔하게 사용할 수 있는 방법은 병렬로 실행하는 것 입니다. 병렬 실행은 하드웨어의 특성을 이용하여 성능을 높이는 가장 좋은 방법이지만, 병렬로 여러 프로세스나 스레드에서 같은 데이터를 접근하여 읽고 쓰는 과정이 수행될 때, 데이터에 대한 일관성과 안정성을 지키지 못하는 문제가 발생하게 됩니다. (다른말로 무결성 을 위배한다고 말합니다.)
멀티 스레드나 멀티 프로세스 환경에서 데이터에 대한 무결성을 지키는 것은 매우 중요합니다. 이것은 소프트웨어를 사용하는 사용자에게 데이터에 대한 신뢰성을 보장하지 못하여 사용자 경험이 떨어지는 문제를 초래할 수 있기 때문입니다.
운영체제, 데이터베이스의 트랜잭션 등 의 CS 교과목에서 저는 이미 이와 관련한 내용들을 충분히 학습했었습니다. 하지만, Java 기반의 Kotlin 언어로 구현하는 안드로이드 앱에서 이를 실질적으로 해결하는 방법들에 대해서는 미숙했었습니다.
이번 포스팅에서는 멀티스레드나 멀티 코어 환경에서 구체적으로 어떤 문제들이 발생하며, 어떻게 발생할 수 있고, Java 기반의 Kotlin 언어로 이를 어떻게 해결할 수 있는지 의 방법들에 대해 정리해보고자 합니다.
Race Condition
동시에 여러 스레드나 프로세스가 동일한 데이터에 접근하여 읽기 만 수행할 경우 문제가 발생하지는 않습니다. 데이터의 변화가 없는 상태에서 읽었기 때문에 동일한 데이터의 결과를 얻었을 것입니다. 이렇게 특정 작업을 수행했을 때 예측되는 결과가 나오는 경우 일관성 또는 안정성 을 보장하고 “데이터가 무결하다”는 의미로 무결성 을 만족한다고 합니다.
하지만, 읽기 와 쓰기 를 동시에 수행하는 경우는 말이 달라집니다. 누가 먼저 데이터를 읽고, 쓰기를 수행했느냐 에 따라 그 결과가 달라지게 됩니다. 이렇게 결과를 예측할 수 없는(일관성을 보장할 수 없는) 경우를 Race Condition 이라고 부릅니다.
Race Condition 은 “경쟁 상태” 라는 뜻입니다. 두개 이상의 스레드나 프로세스가 서로 공유 자원에 접근하기 위해 경쟁하여 누가 먼저 수행되었느냐에 따라 그 결과가 항상 달라지고 일관성을 보장할 수 없는 문제를 통칭합니다. 보통 이러한 경우 병렬 실행되는 스레드나 프로세스들의 접근을 제한하여 순차적으로 실행하도록 만들어 해결합니다. 현대 프로그래밍에서는 상호 배제 를 통해 이를 실현합니다. 이 방법은 특정 작업을 실행하는 스레드나 프로세스들을 순차적으로 처리하여 그 결과를 예측 가능하게 만들어 주지만, 병렬 실행의 목적이었던 성능 개선의 이점을 잃어버리게 됩니다.
상호 배제(Mutual Exclusion)
상호 배제는 공유 자원에 대해 lock 과 unlock 을 통해, 접근 가능한 스레드를 제한함으로써 동시성에 대한 문제를 해결하는 방법을 말합니다. 이는 멀티 스레드나 멀티 코어 환경에서 공유 자원에 대해 동시 접근을 제한하고, 순차적으로 접근하도록 만듭니다. 이때, 공유 자원에 대한 영역을 임계 영역 이라고 부릅니다.
lock 은 스레드가 임계 영역에 접근하여 더 이상 다른 스레드가 접근하지 못하도록 점유하기 위한 방법이며, unlock 은 임계 영역을 점유했던 스레드가 자신의 작업을 모두 마치고 공유 자원에 대한 점유를 해제하여 다른 스레드가 접근 가능하도록 만드는 방법 입니다.
Mutex
상호 배제는 영어로 Mutual Exclusion 이라고 부르며, 이를 줄여 Mutex 라고 부릅니다. 코틀린에서 상호 배제를 사용하여 가장 간단하게 동기화 할 수 있는 방법은 Mutex 클래스를 생성하고 lock(), unlock(), withLock() 메소드를 이용하는 것입니다.
fun main() {
val mutex = Mutex()
var x: Int = 0
CoroutineScope.launch {
repeat(100) {
mutex.lock()
x++
mutex.unlock()
}
}
println(x)
}
위 예시처럼 mutex.lock() 과 unlock() 사이에 존재하는 연산들에 대해 동기화를 실행하는 코드를 작성할 수 있습니다. 하지만 이 방법은 lock() 과 unlock() 사이에서 예외가 발생하는 등의 문제로 인해 unlock() 이 호출되지 않는 문제를 초래할 수 있는 안전하지 못한 방법입니다. 이를 대비하여 withLock() 을 사용하는 것이 바람직합니다.
fun main() {
val mutex = Mutex(Any)
var x: Int = 0
CoroutineScope.launch {
repeat(100) {
mutex.withLock {
x++
}
}
}
println(x)
}
withLock() 은 중단함수이며, 코루틴과 호환되는 함수입니다. 이는 내부적으로 finally 블록을 통해 mutex 의 unlock() 을 호출해 주기 때문에 예외 상황에서도 unlock() 이 호출되는 것을 보장해줍니다.
상호 배제를 이용하면 동시성에 대한 문제를 해결할 수 있습니다. 하지만, 특정 상황에서 추가적인 문제가 발생할 수 있습니다.
Dead Lock
만약, A 스레드가 A1 임계 영역을 점유하고 있고, B 스레드가 B1 임계 영역을 점유하고 있다고 가정해 봅시다. 이 때, A 스레드가 B1 임계 영역에 접근하기 위해 B가 unlock 하기를 기다리고 있고, B 스레드는 A1 임계 영역에 접근하기 위해 A 가 unlock 하기를 서로 기다리고 있는 상황이라면, 서로 영원히 서로의 자원을 내놓기를 기다려 Blocking 되어 버리는 상황이 발생할 수 있습니다. 이런 상황을 교착 상태(DeadLock) 라고 부릅니다.
구체적으로 Mutex 로 lock 을 획득한 상태에서 다시 lock 을 획득하려는 경우에서 Dead Lock 이 발생할 수 있습니다.
fun main() {
val mutex = Mutex(Any)
var x: Int = 0
CoroutineScope.launch {
repeat(100) {
mutex.withLock { // 1
mutex.withLock { // 2
x++
}
}
}
}
println(x)
}
이는 lock() 을 통해 임계 영역을 점유한 상태에서 한번더 lock() 을 호출하면, 2번째 lock() 호출은 1번째의 unlock() 이 호출될 때 까지 대기하지만 1번째의 unlock() 은 2번째가 BLOCKED 상태로 lock 을 획득하기 위해 대기되면서 영원히 호출될 수 없기 때문에 Dead Lock 이 발생합니다. 자바에서는 Dead Lock 에 Safe 하도록 구현되지 않기 때문에 보통 Dead Lock 이 발생할 조건들을 만족하지 않게 구현하거나, 이러한 상황을 회피하도록 미리 만들어진 클래스들을 이용하는 것이 좋습니다.(이에 대한 구체적 예시나 조건들은 나무위키 와 자바 레퍼런스 를 참고하시면 되겠습니다.)
Mutual Exclusion 은 임계 영역에 대한 lock 과 unlock 을 통해 동시 접근을 막는 추상적 개념 입니다. 이를 실질적으로 소프트웨어로 구현하는 방법들에는 데커, 피터슨 알고리즘이 있었습니다. 하지만 이들에는 Busy waiting 과 같은 문제들이 있었고, 이를 해결하여 소프트웨어로 구현한 방법이 세마포어 알고리즘 입니다.
세마포어
기존의 알고리즘에서는 현재 스레드가 임계 영역을 다른 스레드가 점유하고 있는지 또는 없는지를 지속적으로 무한 반복문을 돌면서 확인하는 바쁜 대기(Busy waiting) 방법을 이용했습니다. 이 방법은 지속적 폴링을 실행하면서 CPU 자원을 낭비하게 되는 원인을 초래했습니다. 이 문제를 해결하기 위해 임계 영역에 접근하기 위해 대기하는 스레드들을 반복문으로 busy waiting 하지 않게 하고, 저장 공간에 넣어 대기 시켜 놓았다가 임계 영역에서 작업을 마치고 나오는 스레드가 대기 중인 스레드를 깨워주도록 만든 방법이 세마포어 알고리즘 입니다.
세마포어는 정수 타입의 조건 변수 S 를 가지며 P() 와 V() 연산을 통해 Mutex 를 구현합니다.
- P() 연산: S 의 값이 0 보다 큰지 확인하고, 0 보다 크다면 1감소 시킨 후 임계 영역에 진입한다. 그렇지 않다면, Wait Set (또는 Wait Queue) 에 들어가 대기한다.
- V() 연산: 임계 영역에 진입했던 스레드가 나오면서, S 의 값을 1 증가시킨다. 이때, Wait Set (또는 Wait Queue) 에 존재하는 스레드가 있으면 깨워줘 대기중인 스레드가 임계영역에 진입할 수 있도록 해준다.
- S: 임계 영역에 진입 가능한 스레드의 수를 세는 카운팅 변수 이다. 이 조건 상수를 통해 모든 스레드들이 협력할 수 있어 Busy waiting 을 하지 않아도 된다.
세마포어에는 2가지 종류로, 카운팅 변수를 2로 제한한 이진 세마포어 와 3 이상인 카운팅 세마포어 로 나뉩니다. 이진 세마포어의 경우 Mutex 로 치환될 수 있으며, 구체적 구현 방법이 적용된 사례가 됩니다.
자바에서는 뮤텍스와 세마포어를 활용하여 더 고차원 적인 방법을 통해 동시성의 문제를 해결하기 위한 추상화된 전략을 제공하고 있습니다.
Monitor
기본적으로 자바는 Monitor 라는 객체를 통해 동시성에 대한 문제를 해결하기 위한 추상화된 매커니즘을 제공합니다. 자바에서 모든 객체는 모니터라는 객체를 별도로 가지고 있으며, 모니터를 기반으로 상호배제 와 협력 을 제공합니다.
모든 객체는 각각의 임계 영역인 모니터를 가지고, 스레드가 lock 과 unlock(상호 배제) 을 통해 임계 영역을 점유하거나 이양할 수 있습니다. 자바기반의 코틀린에서는 직접 lock 또는 unlock 메소드를 호출하지 않고, 내부적으로 모니터를 이용하여 추상화된 전략으로써 제공되는 synchronized 어노테이션나 함수를 활용하여 동기화 매커니즘을 활용할 수 있습니다.
class Example(private var x: Int = 0) {
fun inc() {
synchronized(this) {
x++
}
}
}
여러 스레드에서 Example 클래스의 x 값을 증가시키는 함수 inc() 를 호출한다고 했을 때, 내부에서 synchronized 블럭으로 x 값을 증가시키는 코드를 감싸면 해당 코드의 실행을 모든 스레드들에 대해 동기화 해줍니다. 따라서 x 값을 증가시키는 연산에서 일관성이 보장될 수 있습니다.
synchronized 함수의 인자로 this 를 전달하고 있는데, Example 클래스의 인스턴스를 전달하고 내부적으로는 해당 인스턴스가 보유한 모니터를 이용합니다. 결과적으로 현재 스레드가 Example 인스턴스의 모니터 제어권을 획득하게 되고, 다른 스레드는 해당 객체의 제어권을 획득하기 위해 BLOCKED 상태로 Entry Set 에서 대기하게 됩니다.
또한, 자바의 모니터는 세마포어를 기반으로 동작하기 때문에 현재 스레드가 임계 영역의 점유권을 이양하기 위해 다른 스레드가 점유하도록 Entry Set 이나 Wait Set 에서 대기 중인 스레드를 깨울 수 있습니다. 이 과정에서 별도의 제어를 받지 않고 스레드들간에 모니터 객체의 wait(), notify(), notifyAll() 과 같은 메소드들을 이용하여 상호 협력 하는 방식으로 동작 합니다.
wait(), notify(), notifyAll()
기본적으로 자바의 스레드들은 우선 순위 스케줄링(우선순위가 같은 경우 FIFO)과 라운드 로빈 방식으로 동작하여, 특정 스레드가 임계 영역을 점유중인 상태에서 도중에 다른 스레드가 끼어들(interrupt) 수 있는 함수인 wait() 함수를 제공합니다. 이 함수를 사용하면 현재 모니터의 lock 을 획득한 스레드가 동작을 중단하고 Wait Set 에서 대기하며, Entry Set 에서 임계 영역의 lock 을 획득하기 위해 BLOCKED 상태로 대기중인 스레드 중 우선순위가 높은 스레드가 lock 을 획득하게 됩니다.
이후, 해당 스레드가 모든 작업을 마치고 notify() 메소드를 호출하면, 스레드가 종료되면서 Wait Set 에서 대기하던 가장 우선순위가 높은 스레드를 깨워 다시 모니터의 제어권을 획득하고 남은 작업을 이어서 처리할 수 있도록 합니다. 또한, wait() 의 오버로딩 함수로 timeout 시간을 파라미터로 전달하는 경우 다른 스레드가 notify 해주지 않아도 지정된 시간이 지나면 자동으로 깨어날 수 있으며, notifyAll() 을 호출할 경우 Wait Set의 모든 스레드가 깨어나게 되고, 이들이 경쟁하여 모니터의 제어권을 획득하게 됩니다.
Entry Set 과 Wait Set
모니터를 점유하려고 시도한 경우 만약 점유중인 스레드가 있다면, 해당 스레드는 Entry Set 에서 BLOCKED 상태로 대기하게 됩니다. 그리고 모니터를 점유하는 스레드가 wait() 메소드를 호출하여 모니터의 제어권을 이양 하고자 한다면, 해당 스레드는 WAITING 상태로 Wait Set 에서 대기하게 되며, Entry Set 에서 대기하는 스레드 중 가장 우선순위가 높은 스레드를 깨워줍니다.
이후, 해당 스레드가 모든 작업을 마치면 notify() 혹은 notifyAll() 을 호출해야 하며, 호출한 경우 Wait Set 에서 대기중인 스레드 중 가장 우선순위가 높은 스레드를 깨워줍니다. 그리고 깨워진 스레드는 남은 본인의 작업을 다 마치고 다시 Entry Set 에서 대기중인 스레드 중 우선순위가 가장 높은 스레드를 깨워주는 방식으로 동작하게 됩니다.
이외에도 Thread.Sleep() 이나 join() 과 같은 메소드를 호출해도 마찬가지로 해당 스레드는 WAITING 상태가 되며 Wait Set 에 진입하게 됩니다.
Mutex 를 구현하는 방법들은 병렬 실행 이 아닌 순차 실행 으로 만들어 멀티 스레드나 프로세스의 성능 개선에 대한 이점을 잃게 만듭니다. 병렬 실행을 유지하면서 즉, Lock 과 Unlock 없이 “동기화를 만족할 수 있는 방법은 없을까?” 하고 고안된 방법이 락-프리(Lock-Free) 알고리즘 입니다.
Lock-Free 알고리즘
Lock 을 하지 않고 병렬 실행을 유지하면서 동기화를 할 수 있는 대표적인 방법으로 CAS(Compare And Set) 가 있습니다. CAS 알고리즘은 원본 데이터를 캐싱하여 캐싱한 데이터의 복사본에 쓰기 연산을 수행하고, 복사본을 원본데이터에 적용할 때, 캐싱한 데이터와 원본 데이터를 비교하여 다른 경우 쓰기를 취소하고 재시도하는 알고리즘 입니다. 간단하게 이방법은 공유 자원에서 값을 스레드 스택에 복사하고, 연산을 수행한 뒤, 다시 공유자원에 적용하는 과정에 대해 원자성(Atomic) 을 보장하는 방법입니다.
구체적으로 동시성 환경에서 두개의 스레드는 각각 독립적인 스레드 스택을 보유할 것이고, 각 스레드 스택에 공유 자원을 복사한 뒤 복사본에 연산을 수행하고 나서 이 결과를 적용하기 전에 복사했던 원본과 공유자원을 비교하여 같았다면, 현재 스레드가 공유 자원에 연산을 수행하고 적용하기 까지의 과정에 다른 스레드가 끼어들지 않았다는 것을 확신하여 현재 스레드의 연산 결과를 공유 자원에 다시 적용해도 동시성 문제가 없음을 보장할 수 있습니다. 하지만, 달랐다면 중간에 다른 스레드가 공유 자원에 접근하여 데이터를 변경시켰기 때문에 동시성 문제가 발생할 수 있어 현재 스레드의 연산을 취소하고 처음부터 재시도 하게 됩니다.
이를 실제로 구현하여 언어 수준에서 제공되는 대표적 예시가 Java 의 Atomic 입니다.
Atomic
Atomic 은 Int, Double, Long 과 같은 특정 타입들에 대해 Lock-Free 알고리즘 중 하나인 CAS 를 이용하여 Non-Blocking 동기화를 지원해주는 클래스 입니다. 구체적 예시로 AtomicInteger 를 살펴보겠습니다.
public class AtomicInteger extends Number implements java.io.Serializable {
private volatile int value;
public final int get() {
return value;
}
public final void set(int newValue) {
value = newValue;
}
private static final VarHandle VALUE;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
VALUE = l.findVarHandle(AtomicInteger.class, "value", int.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
public final boolean compareAndSet(int expectedValue, int newValue) {
return VALUE.compareAndSet(this, expectedValue, newValue);
}
}
AtomicInteger 클래스에 존재하는 VarHandle 타입의 Value는 내부에 Volatile 키워드 가 붙은 value 의 값에 원자적으로 접근하기 위한 멤버변수 입니다. 이는 compareAndSet() 함수와 같이 동기화가 필요한 메소드에서 호출되는데, 1.value 를 가져와서 2. value 를 newValue 로 업데이트하는 두 단계 사이에 다른 스레드가 끼어들어 쓰기 연산을 수행할 수 없도록 원자적으로 실행하기 위해 존재하는 Delegate 입니다.
하지만 하드웨어 아키텍처에 대응되는 JVM 구현상 메인 메모리에서 값을 읽은 후 CPU-캐시에 저장하여 좀 더 빠르게 데이터를 읽어 오기 위한 매커니즘을 사용하기 때문에 실제로 스택 영역의 스레드가 값을 저장하면 CPU-캐시에 저장되고, 이 값이 메인 메모리에 저장되기 까지 시간이 걸리게 되면서 다른 스레드가 그 값을 읽었을 때 기대되는 값이 아닐 수 있는 가시성 문제가 발생할 수 있습니다.
따라서 value 라는 실제 값이 존재하는 변수에 Volatile 키워드가 작성되어 있습니다. Volatile 키워드는 CPU-캐시에서 값을 읽지 않고, 항상 메인 메모리로부터 값을 읽고 쓰도록 만드는 키워드 입니다. 물론, Volatile 을 남용하게 되면 메인메모리에서 항상 데이터를 접근 하는 것은 CPU-캐시를 이용하는 것보다 느리므로 성능 문제가 발생할 수 있습니다. 결론적으로 Atomic 클래스는 Volatile 을 통해 JVM 구현상의 가시성 문제를 해결하면서, 여러 스레드가 동시에 AtomicInteger 로 접근하면서 발생할 수 있는 동시성 문제를 VarHandle 로 Delegate 하여 원자성을 보장함으로써 동기화를 제공합니다.
CAS 는 병렬 실행을 유지하면서 즉, 성능을 높이면서 동기화를 해줄 수 있는 좋은 방법이지만, 특정 상황에서는 문제가 발생할 수 있습니다. 이에 대한 대표적 문제가 ABA 문제 입니다.
Atomic 의 문제점
ABA 문제는 스택과 같은 자료구조에서 A->B->A 순서로 데이터를 쌓고, A 와 B를 POP 한 뒤에, 다시 A 를 PUSH 한 경우 스택 포인터(SP)가 가르키는 A 는 이전과 같으므로 스택에 변화가 없었다고 판단하면서 발생하는 동시성 문제 입니다.
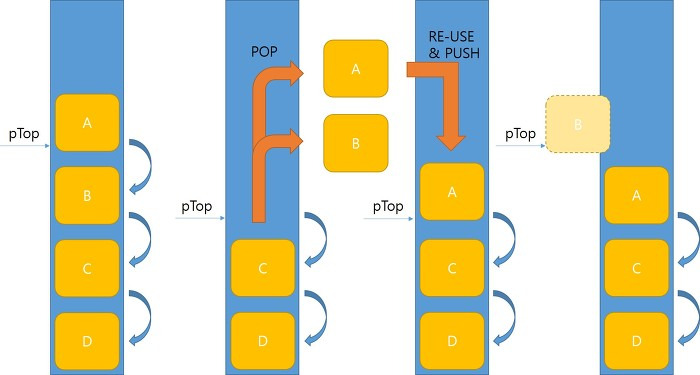
첫번째 스레드가 A 를 POP 하기 위해 current 로, B 를 next 로 설정한 상태에서, 중간에 두번째 스레드가 끼어들어 A와 B를 POP 합니다. 이후 세번째 스레드가 A 를 PUSH 하면, 첫번째 스레드 입장에서는 정상적으로 POP 하려는 A가 존재하므로 문제가 없어 작업을 실행합니다. 하지만 next 로 설정되어 있지만 지금은 존재하지 않는 B 를 current 로 변경하고 있는 문제가 발생하게 됩니다. 이 상황은 궁극적으로 단순히 데이터의 읽기 및 쓰기에 대해서는 원자적으로 실행되지만, 그 보다 더 큰 범위내에서의 원자적 접근이 필요한 경우에 발생할 수 있는 문제 입니다.
또 이것을 해결하기 위해 주소값 뿐만아니라 POP 대상에 대해서도 저장하는 Double-CAS 를 이용할 수도 있습니다. 물론, 이는 근본적 문제를 해결하기 보다는 특정 사례를 해결하는 방법입니다.
ABA와 같은 문제뿐만 아니라, Google 의 Abseil 팀이 작성한 문서 에 따르면, 메모리 재배치 문제로 인해 미묘한 버그가 발생할 수 있음을 경고하고 있습니다. 일반적으로 어셈블리 수준에서 memory_order_seq_cst과 같은 엄격한 메모리 접근 순서를 부여하는 명령어가 아닌 Relaxed ordering 명령어를 사용할 경우 메모리 재배치 가 일어날 수 있습니다.
가령, 다음과 같은 코드가 있다고 생각해 봅시다.
data = 100
flag = true
코드는 위와 같이 data 에 100을 할당한 후에 flag 를 true 로 만들지만, 실제로 어셈블리 수준에서는 컴파일러가 코드를 최적화 하는 과정에서 다음과 같이 메모리 재배치가 일어날 수 있습니다.
flag = true
data = 100
이와 같은 경우, 만약 flag 와 data 가 순서 의존성이 있는 경우 미묘한 버그가 발생할 수 있습니다. 물론, 싱글 스레드에서는 이런 문제가 가시화 되지 않습니다. 하지만 멀티 스레드 환경에서 두 변수가 공유자원 인 경우, 이 두 변수를 각각 Atomic 으로 선언하더라도 각 변수의 읽기 및 쓰기 작업이 원자적으로 수행되지, 두 변수 모두에 대한 읽기 및 쓰기가 원자적으로 수행되지 않습니다. 심지어 메모리 재배치 까지 발생하는 상황에서 두 변수에 순서 의존성이 있다면, 미묘한 버그가 발생할 가능성이 있다고 언급합니다.
또한, x86 과 달리 ARM CPU 아키텍처에서는 memory_order_seq_cst과 같은 엄격한 메모리 접근 순서를 부여해야 하는 명령어를 만들기 위해서 특별히 memory fense 를 추가해야 하는 오버헤드가 발생하기 때문에 오히려 synchronized{} 를 이용하는 것 보다 느리다고 언급합니다. 만약, 공유 변수가 여러개이고 각각의 변수를 모두 Atomic 으로 생성한다면 오버헤드가 가중될 수 있습니다. 따라서, 이런 경우에는 Atomic 변수를 생성하고, 유지 관리하는데 비용이 많이 들기 때문에 이미 만들어진 자료구조 및 API 들을 활용하거나 그냥 synchronized{} 를 이용하는 것을 권장한다고 언급합니다.(ARMv8.1 에서는 CAS 및 LAA 연산에 대해 원자적으로 수행하는 명령어를 지원하는 LSE(Large System Extension) 으로 최적화하여 성능을 개선하고 있다고 언급되고도 있습니다.)
댓글남기기