
[Kotlin] Primitive types 와 boxing type
Aideo 프로젝트를 진행하는 과정에서 Coroutines.Channel 을 활용한 병렬 파이프라인을 구축했었습니다. 그런데, 성능 및 메모리 효율성을 좀 더 개선하기 위한 리펙토링 과정에서 의도치 않은 실수들을 발견하고 이를 개선한 경험을 이번 포스팅에 남겨보려 합니다.
문제점
거두절미하고 먼저 원래의 코드를 먼저 살펴 보겠습니다.
launch {
val windowSize = 512
val buffer = FixedChunkBuffer(windowSize)
val resumeSignal = Channel<Unit>(capacity = 1)
val job = launch {
for (i in extractedAudioChannel) {
buffer.write(i)
if (buffer.totalSamples >= windowSize)
resumeSignal.send(Unit)
}
resumeSignal.close()
}
launch {
while (job.isActive || buffer.totalSamples >= windowSize) {
val chunk = buffer.readChunk()
if (chunk != null) {
vad.acceptWaveform(chunk)
if (vad.isSpeechDetected()) {
inferenceVadAndSd()
}
} else {
try {
resumeSignal.receive()
} catch (e: Exception) {
if (e is ClosedReceiveChannelException)
break
}
}
}
vad.acceptWaveform(buffer.flush())
vad.flush()
inferenceVadAndSd()
inferenceAudioChannel.close()
}
}
기존의 의도는 VAD(Voice Activity Detection 추론의 입력이 512 sample size 를 요구하기 때문에, 두 코루틴으로 분리하여 병렬로 하나의 코루틴은 전처리(chunk 생성), 다른 하나는 VAD 이후의 추론 후 결과를 SpeechRecognition 추론 채널로 전송하는 것 이었습니다. 하지만, 해당 코드에서는 여러 문제들이 있었습니다.
- 512 샘플 사이즈의 Chunk 와 추론 실행을 병렬로 하는 것의 실질적 Performance 이득이 없다는 문제
- 512 샘플 사이즈의 Chunk 생성에 오히려 객체 할당 오버헤드가 가중되는 문제
첫번째 문제부터 살펴보겠습니다.
처음 의도는 VAD 가 요구하는 입력이 512 개 만큼의 float 배열 이었기 때문에, 전처리와 추론을 분리하고자 하는 목적으로 두 작업을 두개의 코루틴으로 병렬 실행하도록 구현했었습니다. 하지만 전처리 로직을 분리하고 테스트 가능성을 확보하는 것 까지는 좋았으나, 두개의 코루틴으로 굳이 병렬 실행하여 얻는 이점이 하나도 없었습니다.
어차피 두번째 코루틴에서는 VAD 로 분할된 샘플을 입력하고 polling 으로 확인하며, FixedChunkBuffer 에서도 내부적으로 read() 와 write() 함수로 공유 자원에 동시에 접근하기 때문에 mutex 로 동기화 해야 합니다. 그러므로 사실상 병렬 실행이 아닌 순차 실행이 되고, 불 필요한 코드를 작성했을 뿐 이었습니다.
private class FixedChunkBuffer(private val chunkSize: Int = 512) {
private val deque = ArrayDeque<Float>()
private val mutex = Mutex()
var totalSamples = 0
private set
suspend fun write(data: FloatArray) {
mutex.withLock {
repeat(data.size) { idx ->
deque.add(data[idx])
}
totalSamples += data.size
}
}
suspend fun readChunk(): FloatArray? {
return mutex.withLock {
if (totalSamples >= chunkSize) {
val chunk = FloatArray(chunkSize)
repeat(chunkSize) { idx ->
chunk[idx] = deque.removeFirst()
}
totalSamples -= chunkSize
chunk
} else null
}
}
fun flush(): FloatArray {
val chunk = FloatArray(deque.size)
repeat(deque.size) {
chunk[it] = deque.removeFirst()
}
totalSamples = 0
return chunk
}
}
그 뿐만 아니라, FixedChunkBuffer 에서 ArrayDeque<Float> 으로 Float 에 대한 boxing type 을 사용하여 더 큰 메모리 공간 할당이 발생했었습니다. 이번 포스팅의 핵심은 바로 이부분 입니다.
FloatArray vs Array
FloatArray 와 Array<Float> 의 차이는 사실 이전부터 알고 있었습니다만, 후술하겠지만 정확하게 이것이 Aideo 처럼 대용량 메모리를 할당하는 과정에서 이렇게 큰 문제가 될지는 몰랐습니다. 먼저, 이 둘의 차이에 대해 짚고 넘어가겠습니다.
코틀린은 자바 코드의 사용성 관점에서 발생하는 여러 문제들을 개선하기 위해 고안된 언어입니다. 가장 대표적인게 null-safety 이죠. 그래서 자바 기반 코드와의 상호운용성을 지원하기 때문에 자바 코드를 프로젝트 내에 함께 사용할 수도 있고, 자바 기반의 라이브러리를 이용할 수도 있습니다. 이것이 궁극적으로 java 와 같이 bytecode 로 컴파일되고, jvm 위에서 동작하기 때문에 가능한 것이죠. 따라서, 자바를 어느정도 알고 있어야 합니다.
자바에서는 primitive types 와 이것들에 대한 boxing type 을 지원합니다. 구체적으로 int 타입과 Integer 라는 타입이 존재합니다. int 와 같은 primitive types 들은 스택 혹은 힙 공간에 생성될 수 있지만, Integer 는 int 의 boxing 타입으로써 힙 공간에만 할당되는 객체 입니다. 이는 내부적으로 int 에 해당하는 4바이트 만큼의 정수값 외에도 여러 메타데이터를 포함하게 됩니다. 구체적으로 클래스 정보를 유지하기 위한 포인터와 GC age counter, monitor 와 같은 클래스로써 필요한 정보들이 포함됩니다. 그래서 primitive types 보다 더 큰 메모리 공간을 점유할 수 밖에 없습니다.(일반적으로 primitive types 보다 12 바이트 정도 더 크다고 합니다.)
일반적인 사용 사례에서는 12바이트 정도의 차이가 크지 않기 때문에 문제가 두드러지지 않지만, Aideo 와 같이 수백만개의 float 값이 필요한 경우에는 이것이 성능과 메모리 부담에 큰 문제를 줄 수 있었습니다. 더 큰 메모리 공간을 빈번하게 할당 및 소멸을 야기하는 경우, Full-GC 동작 빈도수가 증가하고 이것이 Stop-The-World(GC 동작 스레드를 제외한 모든 실행을 멈춤) 를 반복적으로 일으키면서 성능에 영향을 줄 수 밖에 없었습니다.
그렇다면 primitive types 만 사용하면 될 것 같은데, 굳이 왜 boxing 타입을 사용해야 할까요? boxing 타입을 사용해야 하는 이유는 이미 앞선 Generic 포스팅 에서도 언급한 바와 같이 제네릭은 런타임에 메모리 효율성을 위해서 타입 파라미터에 대한 정보를 소거하게 됩니다. 소거된 정보는 Object 타입으로 관리되기 때문에 반드시 객체가 되어야 해서 primitive types 를 제네릭의 타입 파라미터로 사용할 수 없습니다.
Kotlin 에서도 마찬가지입니다. Kotlin 은 기본적으로 Int, Float 과 같은 primitive types 를 지원하지만 java 에서 지원하지 않는 Int?, Float? 과 같은 nullable 타입이나 제네릭의 타입 파라미터로 사용되는 Array
그래서 공식문서 에서는 Array
해결
이러한 문제들을 해결한 코드는 다음과 같습니다.
private suspend fun processExtractedAudioWithVad() {
val chunkedProcessor = ChunkedAudioProcessor(windowSize = 512) { chunk ->
vad.acceptWaveform(chunk)
if (vad.isSpeechDetected()) {
inferenceVadAndSd()
}
}
for (samples in extractedAudioChannel) {
chunkedProcessor.feed(samples)
}
val remainder = chunkedProcessor.flush()
if (remainder.isNotEmpty()) {
vad.acceptWaveform(remainder)
}
vad.flush()
inferenceVadAndSd()
inferenceAudioChannel.close()
}
class ChunkedAudioProcessor(
private val windowSize: Int = 512,
private val onChunkReady: suspend (FloatArray) -> Unit,
) {
private val buffer = FloatArray(windowSize)
private var position = 0
suspend fun feed(samples: FloatArray) {
var offset = 0
if (position > 0) {
val needed = windowSize - position
val toCopy = minOf(needed, samples.size)
samples.copyInto(buffer, destinationOffset = position, endIndex = toCopy)
position += toCopy
offset = toCopy
if (position == windowSize) {
onChunkReady(buffer)
position = 0
}
}
while (offset + windowSize <= samples.size) {
onChunkReady(samples.copyOfRange(offset, offset + windowSize))
offset += windowSize
}
if (offset < samples.size) {
samples.copyInto(buffer, destinationOffset = 0, startIndex = offset)
position = samples.size - offset
}
}
fun flush(): FloatArray = buffer.copyOf(position).also { position = 0 }
}
기존 코드의 의도는 전처리 로직을 분리하는 것 이었기 때문에, 이 의도는 그대로 살려서 ChunkedAudioProcessor 클래스로 분리하였습니다. 또한, 코드의 안정성을 높이기 위해 단위 테스트 코드 또한 작성했습니다.
내부에서는 512 개 만큼의 샘플 수로 분할하기 위해서 여러 오프셋 포인터 변수를 두었고, FloatArray 의 copyInto() 를 활용해 기존 배열을 그대로 사용함으로써 불 필요한 메모리 할당 오버헤드를 방지 하였습니다.
또한, 불 필요한 mutex 와 두개의 코루틴 병렬 실행을 제거하고 하나의 코루틴 내에서 순차 실행시키도록 하여 잘못된 코드들을 재 작성했습니다.
결과
위의 코드 개선이 얼마나 효과가 있었는지 Profiler 를 이용하여 비교해 보았습니다. 결과는 매우 충격적이었습니다.
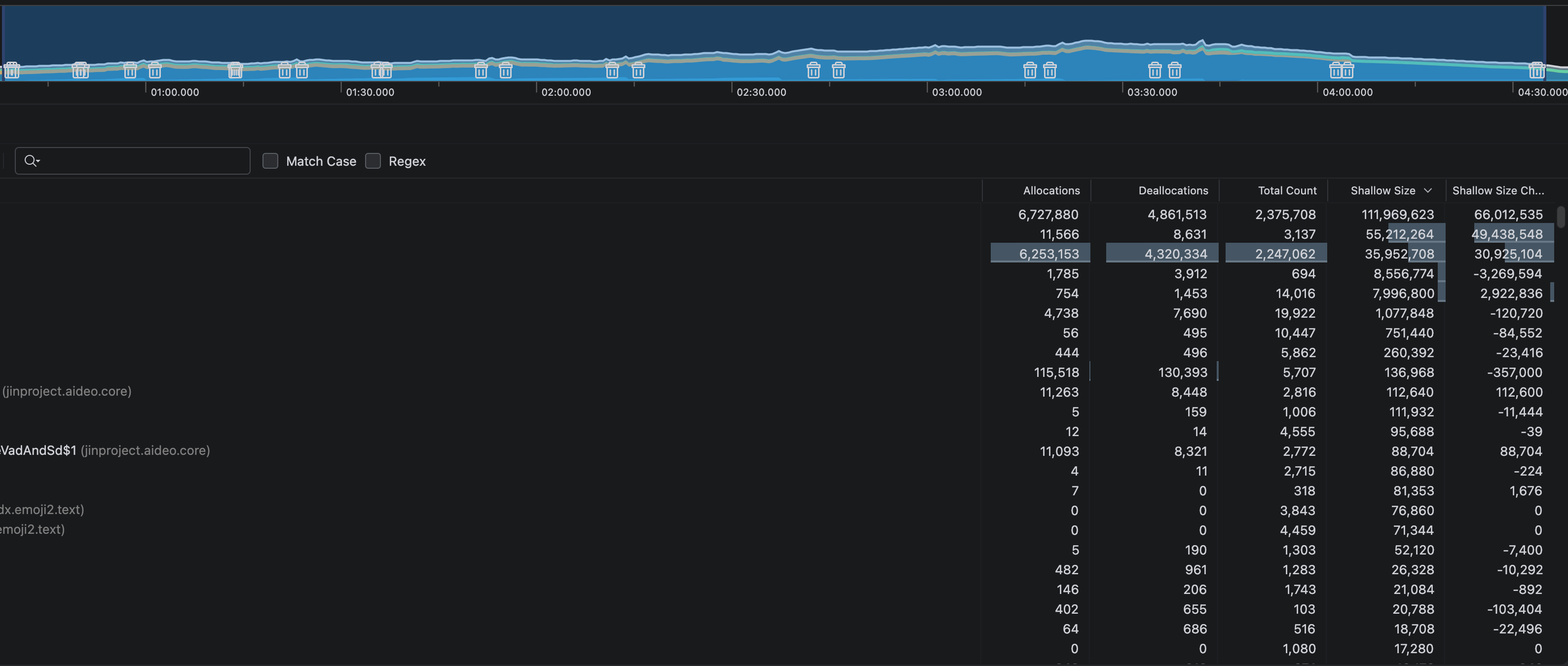
개선 전에는 추론에 걸린 시간이 약 4분30초가 소요됬으며, GC 가 26회, 전체 객체 할당이 670만개 였습니다.
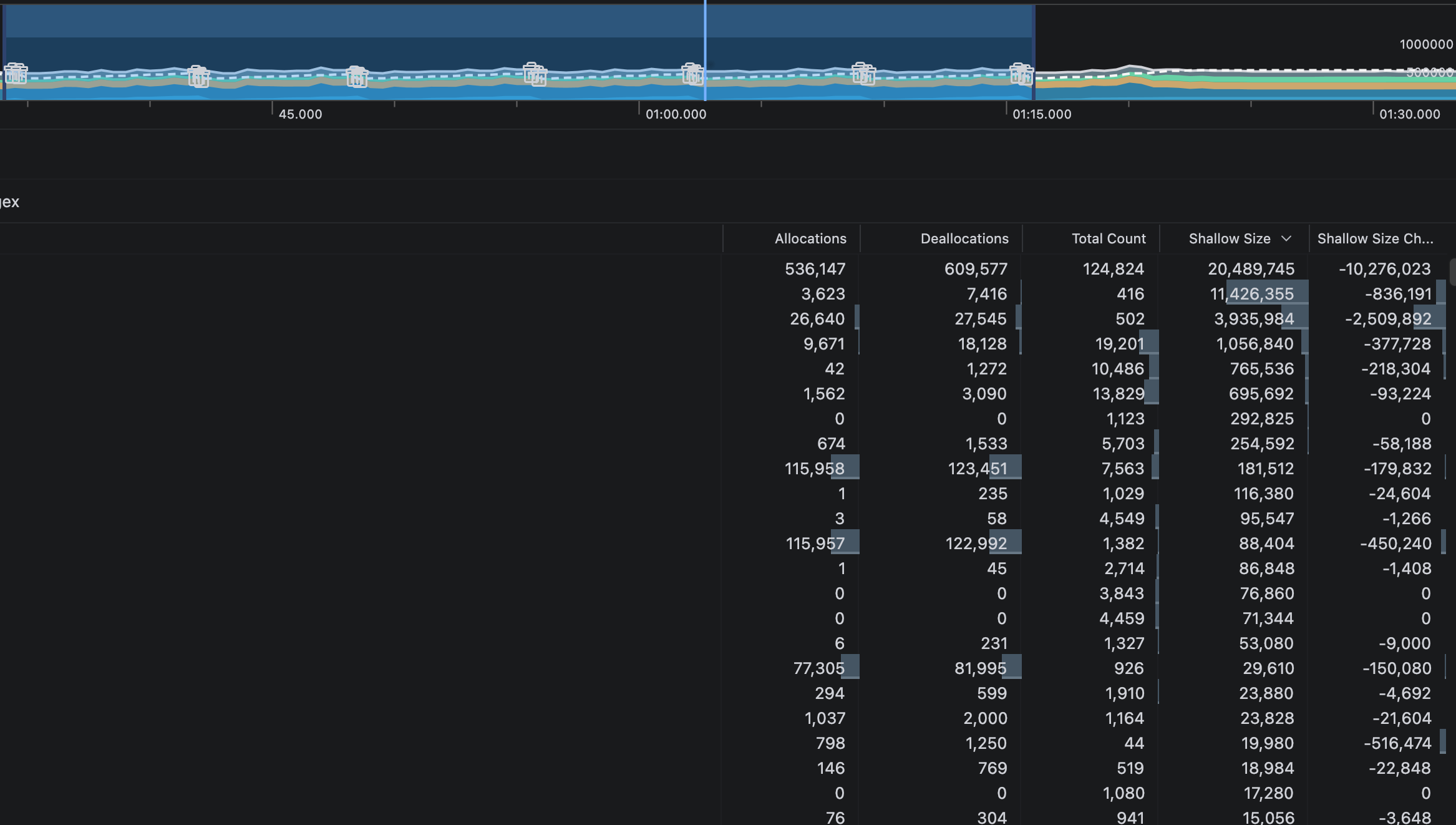
하지만, 개선 후에는 추론에 걸린 시간이 약 1분15초가 소요됬으며, GC 는 14회, 전체 객체 할당이 53만개 였습니다. 단순히 Profiler 로 Memory allocate 만 측정하여 비교했을 때도 큰 차이를 보였습니다. 또한, native memory 공간의 점유율이 개선 전은 700만, 개선 후는 약70만으로 10배 정도의 차이가 났는데, 기존의 FixedChunkBuffer 클래스에서 참조되는 Float 값들이 SpeechRecognition 의 병목 현상으로 인해 지속적으로 쌓여 나가면서 Peek 시점에 큰 메모리 점유를 할 수 밖에 없었고, 이로 인해 메모리에 큰 부담을 줬었습니다.
분명히 Boxing type 과 primitive types 에 대해 알고는 있었지만, 이것을 활용하는 시점에 인지하지 못하는 실수를 해버렸고, 결과적으로 퍼포먼스에 큰 영향을 주게 되었습니다. 앞으로 항상 코드를 작성하는 과정에 깊이 고민해야겠다고 느꼈습니다…
댓글남기기